Explicación del informe P1
De las curvas de rotación a la lente débil: cómo poner a prueba la respuesta gravitatoria media de EFT
Consulta el informe de evaluación original:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
Nota de lectura |
Este es un texto explicativo, no otro informe académico. Se basa en el informe P1 original, conserva las figuras y tablas clave, y añade en cada paso importante una explicación pública de «qué significa esto». |
Este texto solo interpreta las conclusiones de P1 dentro de sus conjuntos de datos, libro de parámetros y protocolo estadístico ya definidos: en la prueba conjunta de curvas de rotación galácticas (RC) y lente débil galaxia-galaxia (GGL), el modelo de respuesta gravitatoria media de EFT queda claramente por delante de la línea base mínima DM_RAZOR probada aquí. |
Este texto no interpreta P1 como una conclusión de que «la materia oscura ha sido derrotada». P1 es solo el primer paso de la serie P; prueba el nivel observable de la «base gravitatoria media» de EFT, no el contenido completo de toda la teoría EFT. |
0 | Entender P1 en cinco minutos: ¿qué se está haciendo exactamente?
Podemos pensar en P1 como un experimento de «verificación cruzada entre sondas». No pregunta solo si un modelo puede ajustar un conjunto de datos; coloca dos lecturas gravitatorias completamente distintas en el mismo banco de auditoría: las curvas de rotación (RC) leen la dinámica en los discos galácticos, mientras que la lente débil galaxia-galaxia (GGL) lee la respuesta gravitatoria proyectada a escalas mayores.
- Las RC funcionan como un «velocímetro»: indican a qué velocidad giran el gas y las estrellas en distintos radios del disco de una galaxia.
- La GGL funciona como una «balanza»: a partir de la ligera curvatura de la luz de fondo causada por galaxias de primer plano, infiere la distribución media de gravedad o masa alrededor de las galaxias a escalas más grandes.
- La pregunta central de P1 es esta: ¿puede un mismo modelo aprender primero una regularidad a partir de las RC y después trasladarla a la GGL sin dejar de ser coherente?
La frase más importante de P1 |
P1 eleva el umbral de comparación desde «qué tan bien ajusta por separado» hasta «si puede cerrar entre sondas». Solo si el modelo rinde bien bajo la correspondencia correcta y la señal colapsa al permutarla es más probable que haya captado una estructura gravitatoria compartida entre RC y GGL. |
Tabla 0 | Los números clave de P1 y cómo leerlos como lector general
Indicador | Lectura dentro de P1 / P1A | Cómo interpretarlo como lector general |
Ajuste conjunto ΔlogL_total | En la comparación principal, EFT frente a DM_RAZOR alcanza 1155–1337 | Diferencia de puntuación total al combinar dos conjuntos de datos; cuanto mayor, mejor es la explicación global. |
Fuerza de cierre ΔlogL_closure | En la comparación principal, EFT alcanza 172–281 y DM_RAZOR 127 | Capacidad de predecir GGL tras inferir solo con RC; cuanto mayor, más «autocoherente entre sondas». |
Control negativo shuffle | Tras permutar RC-bin→GGL-bin, la señal de cierre de EFT cae a 6–23 | Si se rompe la correspondencia correcta, la ventaja debería desaparecer; cuanto más desaparece, más se descartan señales espurias. |
Prueba de presión P1A con múltiples DM | DM 7+1 + DM_STD, manteniendo EFT_BIN como control | P1A no mira solo el DM_RAZOR mínimo: coloca varias ramas DM reforzadas, de baja dimensión y auditables, dentro del mismo protocolo de cierre. |
1 | Por qué hacer P1: ¿dónde está atascada hoy la cosmología a escala galáctica?
El problema de las escalas galácticas sigue siendo difícil porque la «necesidad de gravedad o masa adicional» no es solo un fenómeno de las curvas de rotación. Muchas observaciones muestran una relación muy estrecha entre la materia bariónica visible de las galaxias y las lecturas dinámicas o de lente realmente medidas. Para las rutas de materia oscura, esto implica coordinar con mucha precisión los halos oscuros, la retroalimentación bariónica, la historia de formación galáctica y los errores sistemáticos de observación; para las rutas de gravedad sin materia oscura, implica que un modelo no puede lucir bien solo en RC, sino que también debe mantenerse en la lente débil, en las leyes de escala poblacionales y en los controles negativos.
Esa es precisamente la motivación de P1: no parte de que «la materia oscura está equivocada» ni de que «EFT tiene que ser correcta». Toma una proposición comprobable y la somete a examen: si la respuesta gravitatoria media de EFT deja, en el cierre entre sondas RC→GGL, una señal reproducible y transferible.
Contexto bibliográfico externo: ¿por qué es importante esta ventana RC+GGL? |
La relación de aceleración radial (RAR) propuesta por McGaugh, Lelli y Schombert en 2016 muestra una correlación estrecha, con poca dispersión, entre la aceleración observada trazada por curvas de rotación y la aceleración predicha a partir de la materia bariónica. Esto convierte el acoplamiento bariones–respuesta gravitatoria en un problema inevitable para las teorías a escala galáctica. |
Brouwer et al. 2021 usaron la lente débil KiDS-1000 para extender la RAR a aceleraciones más bajas y radios mayores, comparando MOND, la gravedad emergente de Verlinde y modelos LambdaCDM; también señalaron que las diferencias entre galaxias tempranas y tardías, los halos gaseosos y la conexión galaxia–halo siguen siendo piezas clave de la explicación. |
Mistele et al. 2024 usaron además lente débil para inferir curvas de velocidad circular en galaxias aisladas, informando que no muestran una caída clara hasta cientos de kpc e incluso alrededor de 1 Mpc, y que son compatibles con la BTFR. Esto indica que la lente débil se está convirtiendo en una lectura externa importante para probar la respuesta gravitatoria a escala galáctica. |
Por eso, el valor de P1 no está en ser «el primero en hablar de RC y GGL juntos», sino en ponerlos dentro de un protocolo auditable compuesto por una correspondencia fija, un libro de parámetros, cierre RC-only→GGL, control negativo por shuffle y pruebas de presión P1A con múltiples DM.
2 | Qué significa EFT en P1: no es Effective Field Theory
Aquí, EFT designa la Teoría del filamento de energía (Energy Filament Theory, EFT), no la Effective Field Theory habitual en física. En el informe técnico P1, el uso de EFT es muy prudente: no compite como teoría final completa, sino que primero se comprime en una parametrización observable, ajustable y refutable de la «respuesta gravitatoria media».
Dicho en lenguaje sencillo: P1 no discute todavía todas las fuentes microscópicas de la gravedad adicional ni pretende probar de una vez toda EFT. Solo plantea una pregunta más estrecha y más dura: si existe una cierta respuesta gravitatoria media a escala galáctica, ¿puede explicar primero las RC y luego predecir la GGL al trasladarse de una sonda a otra?
¿Qué parte de EFT captura P1? |
P1 captura la «base gravitatoria media» (mean gravity floor): una contribución promedio, estadísticamente estable y transferible entre muestras. |
P1 no trata todavía la «base de ruido» (stochastic / noise floor): términos aleatorios, diferencias individuales o dispersión adicional que podrían surgir de procesos microscópicos de fluctuación. |
P1 tampoco discute el mecanismo microscópico completo, abundancias, vidas medias ni restricciones cosmológicas globales. Es el primer paso de la serie P, no el veredicto final. |
3 | El plan de la serie P1: por qué el primer paso empieza por la «base media»
La serie P puede entenderse como el programa de búsqueda observacional de EFT. No despliega todas las tesis a la vez; extrae primero la pieza que resulta más fácil de someter a datos públicos. La estrategia de P1 es probar primero el término medio: si la respuesta gravitatoria media ni siquiera cierra de RC a GGL, discutir términos de ruido más complejos o mecanismos microscópicos carecería de una puerta de entrada sólida.
Tabla 1 | Posicionamiento por capas de la serie P
Capa | Pregunta que se plantea | Lugar en P1 |
P1 | ¿Puede la respuesta gravitatoria media cerrar de RC a GGL? | Pregunta principal del informe actual |
P1A | Si fortalecemos el lado DM, ¿la conclusión sigue siendo estable? | Apéndice B: prueba de presión DM 7+1 + DM_STD |
Serie P posterior | ¿Puede ampliarse a más datos, más sondas y errores sistemáticos más complejos? | Dirección de trabajo posterior |
Problemas más profundos | ¿Cómo se conectan el término medio, el término de ruido y el mecanismo microscópico? | Fuera del alcance de las conclusiones de P1 |
4 | Qué datos se usan: qué nos dicen RC y GGL por separado
4.1 Curvas de rotación RC: el «medidor de velocidad» del disco galáctico
Las curvas de rotación registran a qué velocidad giran el gas y las estrellas a distintos radios respecto del centro galáctico. Cuanto mayor es la velocidad, mayor fuerza centrípeta se necesita en ese radio y, por tanto, mayor gravedad efectiva. P1 utiliza la base de datos SPARC; tras el preprocesamiento incorpora 104 galaxias y 2295 puntos de velocidad, divididos en 20 RC-bin.
4.2 Lente débil GGL: la «balanza gravitatoria» a escalas mayores
La lente débil galaxia-galaxia mide cómo las galaxias de primer plano curvan levemente la luz de galaxias de fondo. Corresponde a la respuesta gravitatoria proyectada a escalas más grandes, del orden del halo, y no depende de los detalles de la dinámica del gas en el disco. P1 usa los datos públicos de GGL de KiDS-1000 / Brouwer et al. 2021: 4 bins de masa estelar, 15 puntos radiales por bin, 60 puntos en total, con la covarianza completa.
4.3 Correspondencia fija: por qué 20 RC-bin → 4 GGL-bin es crucial
P1 conecta los 20 RC-bin con los 4 GGL-bin mediante una regla fija: cada GGL-bin corresponde a 5 RC-bin y se promedia con pesos basados en el número de galaxias. Esta correspondencia se mantiene igual para todos los modelos; es una restricción dura para la prueba de cierre y para una comparación justa.
¿Por qué no ajustar la correspondencia después de ver los datos? |
Si se permitiera elegir a posteriori «qué RC-bin corresponden a qué GGL-bin», un modelo podría fabricar cierre ajustando las correspondencias. P1 bloquea de antemano la correspondencia 20→4 y usa un control negativo shuffle para romperla deliberadamente, precisamente para evaluar si la señal de cierre depende de una correspondencia físicamente razonable. |
5 | Modelos y método: ¿qué compara exactamente P1?
5.1 Lado EFT: respuesta gravitatoria media de baja dimensión
En el lado EFT se usa un término de velocidad adicional de baja dimensión para describir la respuesta gravitatoria media: la forma del término adicional está controlada por una función núcleo adimensional f(r/ℓ), donde ℓ es una escala global, y la amplitud se da por RC-bin. Diferentes funciones núcleo representan distintas pendientes iniciales, velocidades de transición y colas de largo alcance, y se usan como pruebas de robustez.
5.2 Lado DM: la comparación principal del texto y el apéndice P1A deben leerse por separado
En la comparación principal, DM_RAZOR es una línea base NFW minimizada y auditable: fija la relación c–M y no incluye halo-to-halo scatter, contracción adiabática, feedback core, no esfericidad ni términos de entorno. La ventaja de este diseño es que controla los grados de libertad y facilita la reproducción; su desventaja es que no representa todos los modelos LambdaCDM ni todos los modelos posibles de halo de materia oscura.
Por eso, en el Apéndice B (P1A), el lado DM se convierte en un conjunto de «pruebas de presión estandarizadas»: sin cambiar la correspondencia compartida ni el protocolo de cierre, se añaden gradualmente ramas de baja dimensión como SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m y la línea base combinada DM_STD, manteniendo EFT_BIN como referencia. P1A puede entenderse así: no se compara solo contra una línea base DM mínima, sino que se coloca un conjunto de mecanismos DM comunes y auditables dentro de la misma «regla de cierre».
Formulación precisa de las conclusiones usada en este texto |
Texto principal: la serie EFT supera de forma clara al DM_RAZOR mínimo en la comparación principal. |
Apéndice B / P1A: con varias ramas DM reforzadas de baja dimensión y auditables, junto con la prueba de presión DM_STD, algunos ajustes conjuntos DM pueden mejorar, pero la fuerza de cierre no elimina la ventaja de EFT_BIN. |
Por tanto, la formulación más prudente es: dentro del alcance de los datos, la correspondencia, el libro de parámetros y el protocolo de cierre de P1/P1A, la respuesta gravitatoria media de EFT muestra una consistencia más fuerte entre conjuntos de datos; esto no equivale a descartar todos los modelos de materia oscura. |
5.3 Prueba de cierre: la gramática experimental más importante de P1
1. Ajustar usando solo RC y obtener un conjunto de muestras posteriores RC-only.
2. Sin permitir un nuevo ajuste con GGL, usar directamente las posteriores de RC para predecir GGL.
3. Calcular, con la covarianza completa, la puntuación predictiva GGL logL_true bajo la correspondencia correcta.
4. Permutar aleatoriamente la correspondencia RC-bin→GGL-bin y calcular el control negativo logL_perm.
5. Restar ambas cantidades para obtener la fuerza de cierre: ΔlogL_closure = <logL_true> − <logL_perm>.
Analogía sencilla |
La prueba de cierre se parece a una repetición de examen en otra sala: el modelo aprende primero en la sala RC y luego responde en la sala GGL. Si de verdad aprendió una regularidad compartida y no una técnica local, debería seguir contestando bien al cambiar de sala; si se baraja deliberadamente la correspondencia entre salas, la ventaja debería desaparecer. |
5.4 Antes de leer las tablas técnicas: cuatro entradas que conviene fijar
Tabla 5.4 | Ruta de lectura de la siguiente serie de tablas técnicas horizontales
Entrada | Qué mirar | Por qué importa |
Tabla S1a | Puntuación total de ajuste conjunto RC+GGL | Responde «al mirar los dos conjuntos de datos juntos, quién ofrece una explicación global más fuerte». |
Tabla S1b | Fuerza de cierre, shuffle y barridos de robustez | Responde «si lo aprendido en RC puede trasladarse a GGL». |
Tabla B0 | Definiciones de múltiples ramas DM reforzadas en P1A | Evita reducir P1 a «solo se comparó con el DM_RAZOR mínimo». |
Tabla B1 | Scoreboard de cierre y ajuste conjunto de P1A | Comprueba si, tras reforzar DM, la ventaja de cierre desaparece. |
Nota de maquetación |
La página siguiente empieza en orientación horizontal para conservar completa la tabla ancha del informe original, sin eliminar columnas ni comprimirla hasta hacerla ilegible. La explicación del texto ya ofrece primero una lectura para el público general; las tablas horizontales sirven para quienes necesiten comprobar números y ramas de modelo. |
Figura 0.1 | Entender de un vistazo el flujo de la prueba de cierre de P1
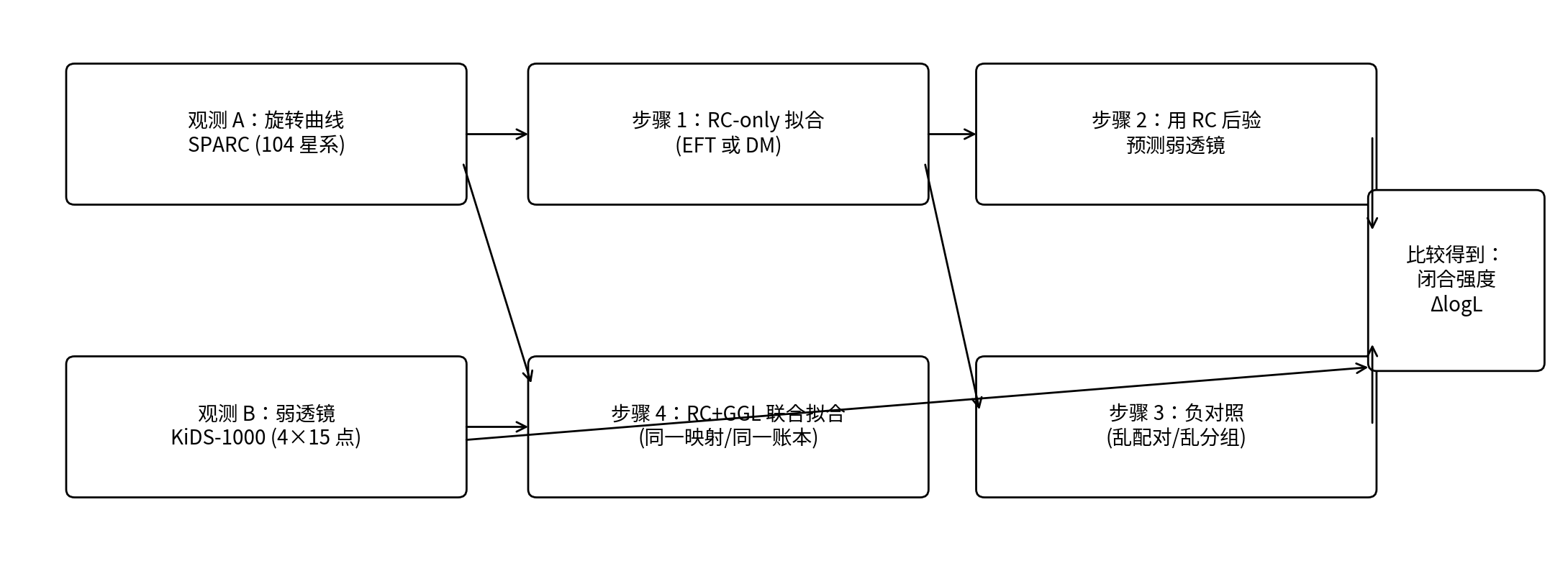
Nota: la cadena superior es la «prueba de cierre» (ajustar solo con RC → predecir GGL con las posteriores de RC); la cadena inferior es el «ajuste conjunto» (RC+GGL se puntúan juntos). A la derecha se compara la correspondencia real con la correspondencia permutada para obtener la fuerza de cierre ΔlogL.
6 | Tablas técnicas clave: tablas principales del informe original y tablas P1A
Tabla S1a | Indicadores principales de ajuste conjunto (RC+GGL, Strict; conservados del informe original)
Modelo (workspace) | Núcleo W | k | logL_total conjunto (best) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabla S1b | Indicadores de cierre y robustez (Strict; conservados del informe original)
Modelo (workspace) | ΔlogL de cierre (true-perm) | ΔlogL tras control negativo shuffle | Rango de ΔlogL en barrido σ_int | Rango de ΔlogL en barrido R_min | Rango de ΔlogL en barrido cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tabla B0 | Definición de las ramas DM reforzadas en P1A (conservada del Apéndice B del informe original)
Workspace | dm_model | Parámetros añadidos (≤1) | Motivación física (núcleo) | Principio de implementación (auditable) |
|---|---|---|---|---|
DM_RAZOR | NFW (fixed c–M, no scatter) | — | Línea base de halo LambdaCDM minimizada y auditable; usada como contraste estricto frente a EFT | Correspondencia compartida fija; libro de parámetros estricto; como baseline se usa solo para comparación relativa |
DM_RAZOR_SCAT | NFW + c–M scatter (legacy) | σ_logc | Existe dispersión en la relación c–M; se aproxima con un scatter log-normal de un parámetro | ≤1 parámetro nuevo; se mantiene la correspondencia compartida; la ganancia de cierre es el criterio de aceptación |
DM_RAZOR_AC | NFW + Adiabatic Contraction (legacy) | α_AC | La caída de bariones puede inducir contracción adiabática del halo; se aproxima con una intensidad de un parámetro | ≤1 parámetro nuevo; no cambia la correspondencia; se reportan cambios en AICc/BIC y ganancia de cierre |
DM_RAZOR_FB | NFW + feedback core (legacy) | log r_core | La retroalimentación puede formar un core en la región interna; se aproxima con una escala core de un parámetro | ≤1 parámetro nuevo; mismo criterio de cierre/control negativo; la mejora RC-only no es el único objetivo |
DM_HIER_CMSCAT | Hierarchical c–M scatter + prior | σ_logc (hier) | Jerarquización más estándar c_i∼logN(c(M_i),σ_logc); afecta a la vez la posterior conjunta de RC y GGL | Prior explícito; c_i latentes marginalizados; se mantiene baja dimensión y auditabilidad |
DM_CORE1P | 1‑parameter core proxy (coreNFW/DC14‑inspired) | log r_core | Usa un proxy core de un parámetro para el efecto principal de baryonic feedback, evitando detalles de alta dimensión de la formación estelar | Se citan referencias estándar; ≤1 parámetro nuevo; vinculado a la prueba de cierre |
DM_RAZOR_M | NFW + lensing shear‑calibration nuisance | m_shear (GGL) | Absorbe el error sistemático clave del lado de lente débil en un parámetro efectivo, reduciendo el riesgo de confundir sistemática con física | El nuisance queda contabilizado de forma explícita; no puede retroactuar sobre RC; los resultados se evalúan sobre todo por la robustez del cierre |
DM_STD | Standardized DM baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Integra simultáneamente las tres objeciones frecuentes más comunes en una línea base estándar que sigue siendo de baja dimensión | Libro de parámetros + criterios de información reportados juntos; cierre como indicador principal; usado como contraste de defensa DM más fuerte |
Tabla B1 | Scoreboard P1A (cuanto mayor, mejor; conservado del Apéndice B del informe original)
Rama del modelo (workspace) | Δk | RC-only best logL_RC (Δ) | Fuerza de cierre ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Cómo leer la Tabla B1 (scoreboard P1A) |
• Δk: grados de libertad añadidos (un valor mayor implica un modelo más complejo; más complejo no significa mejor). • Mirar sobre todo dos columnas: la fuerza de cierre ΔlogL_closure(Δ) (cuanto mayor, más «autocoherente en la transferencia») y Joint best logL_total(Δ) (puntuación total del ajuste conjunto). • El (Δ) entre paréntesis indica la diferencia frente a DM_RAZOR, para facilitar la comparación directa. |
• La pregunta que más busca responder esta tabla es: cuando la línea base DM se «refuerza razonablemente», ¿desaparece la ventaja de cierre? • Pista de lectura: la puntuación conjunta de DM_STD mejora de forma muy clara, pero la fuerza de cierre baja; EFT_BIN sigue manteniendo una fuerza de cierre mayor. |
Resumen en una frase: dentro de este conjunto de refuerzos DM de baja dimensión y auditables, mejorar el ajuste conjunto no produce automáticamente un cierre más fuerte; el cierre, es decir la transferibilidad, sigue siendo el criterio clave. |
7 | Cómo leer los resultados principales
7.1 Ajuste conjunto: al ver los dos conjuntos de datos juntos, la comparación principal da mayor puntuación a EFT
La Tabla S1a y la Figura S4 muestran que, con los mismos datos, la misma correspondencia compartida y una escala de parámetros aproximadamente similar, la serie EFT obtiene frente a DM_RAZOR un ΔlogL_total conjunto de 1155–1337. Para el lector general, esto significa que, bajo la misma regla de puntuación aplicada a RC y GGL en conjunto, el modelo principal EFT logra una puntuación total más alta.
7.2 Prueba de cierre: lo que más quiere subrayar P1 es la «transferibilidad»
Una fuerza de cierre alta indica que los parámetros inferidos por el modelo solo con RC, sin volver a mirar GGL, predicen mejor GGL. En el informe P1, el ΔlogL_closure de EFT es 172–281, mientras que DM_RAZOR alcanza 127. Este resultado es más importante que decir que «ambos ajustan razonablemente bien», porque limita la libertad del modelo en el segundo conjunto de datos.
7.3 Control negativo: por qué el «colapso de la señal» es una buena noticia
Cuando P1 baraja aleatoriamente la correspondencia de grupos RC-bin→GGL-bin, la señal de cierre de EFT cae al orden de 6–23. Para el lector general, este paso equivale a una «prueba antitrampa»: si la ventaja de cierre proviniera solo del código, las unidades, la covarianza o una casualidad de ajuste, tal vez siguiera apareciendo al permutar las correspondencias; pero el resultado real es un colapso de la ventaja, lo que muestra que depende de la correspondencia correcta.
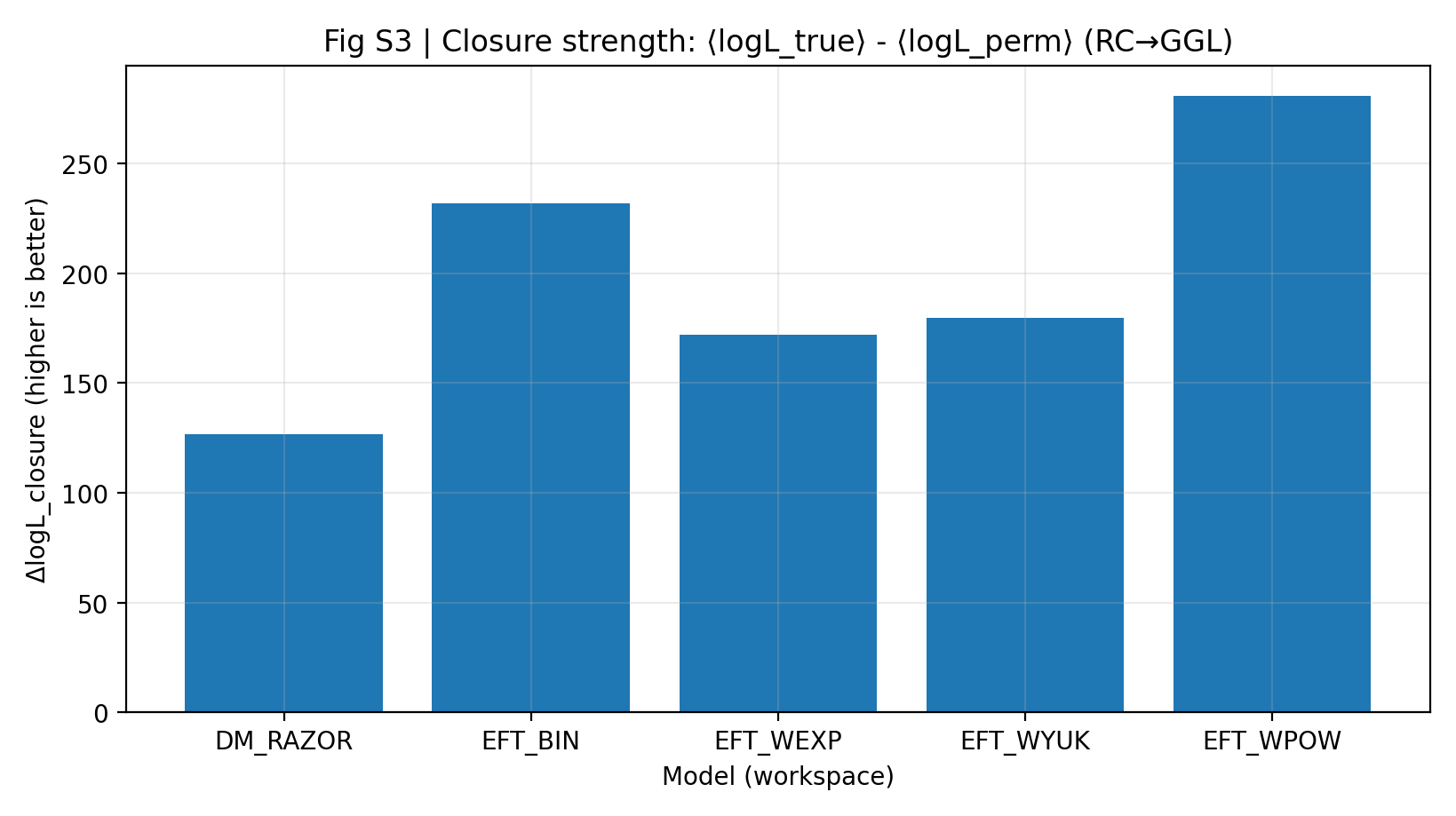
Figura S3 | Fuerza de cierre (cuanto mayor, mejor): ventaja media de log-verosimilitud en la predicción RC-only → GGL.
Cómo interpretar esta figura |
Esta figura es el núcleo de P1. Cuanto más alta es la barra, más se puede transferir a GGL la información que el modelo aprendió de RC. |
La serie EFT queda en conjunto por encima de DM_RAZOR, lo que indica que en el experimento «aprender primero RC y luego predecir GGL» EFT tiene un cierre entre sondas más fuerte. |
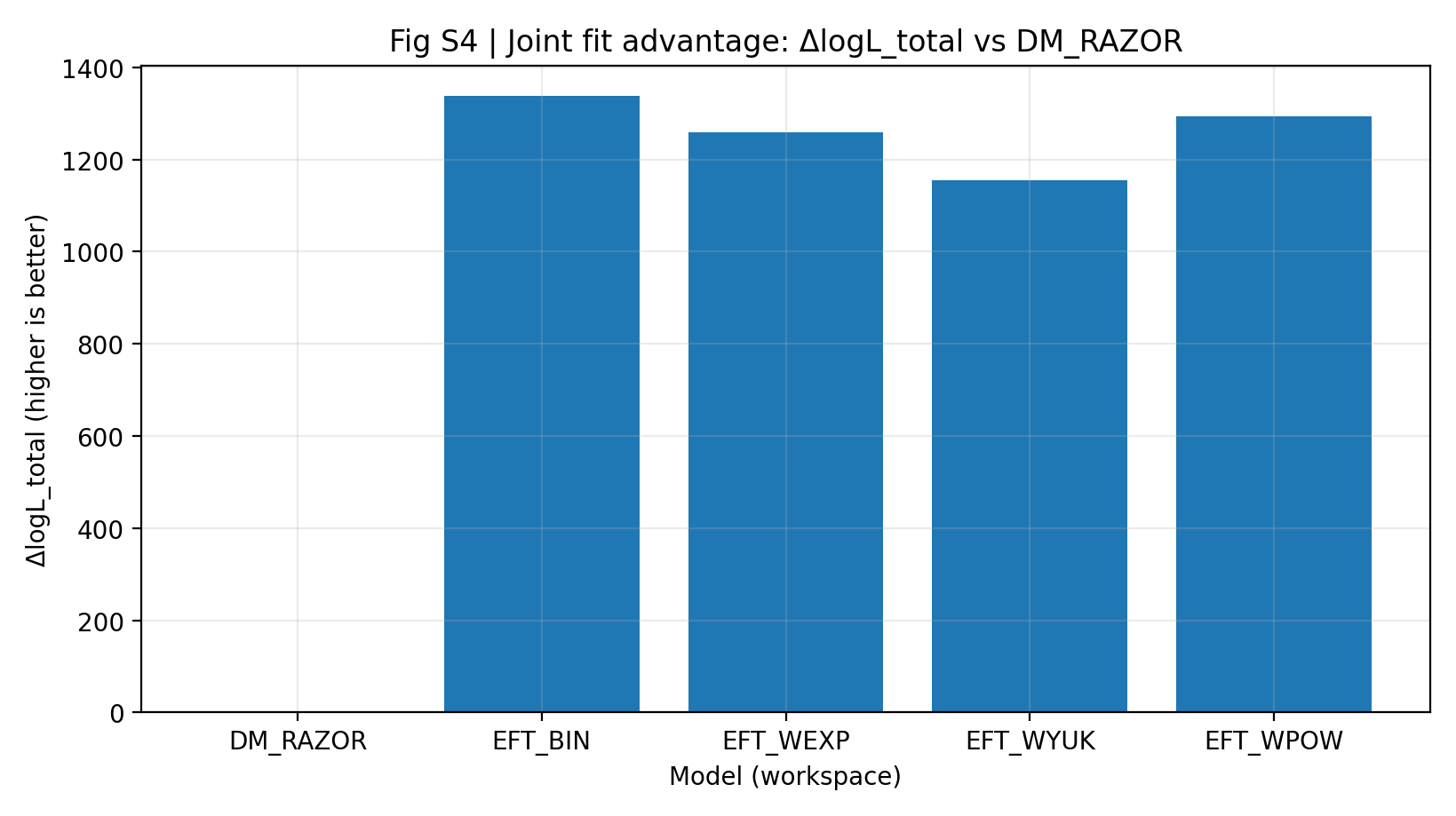
Figura S4 | Ventaja de ajuste conjunto (cuanto mayor, mejor): best logL_total de RC+GGL frente a DM_RAZOR.
Cómo interpretar esta figura |
Esta figura muestra la puntuación total después de combinar RC y GGL. |
Toda la serie EFT queda claramente por encima de 0, lo que indica que la ventaja de EFT en la comparación principal no es un fenómeno local de un único punto, sino el desempeño global del análisis conjunto. |
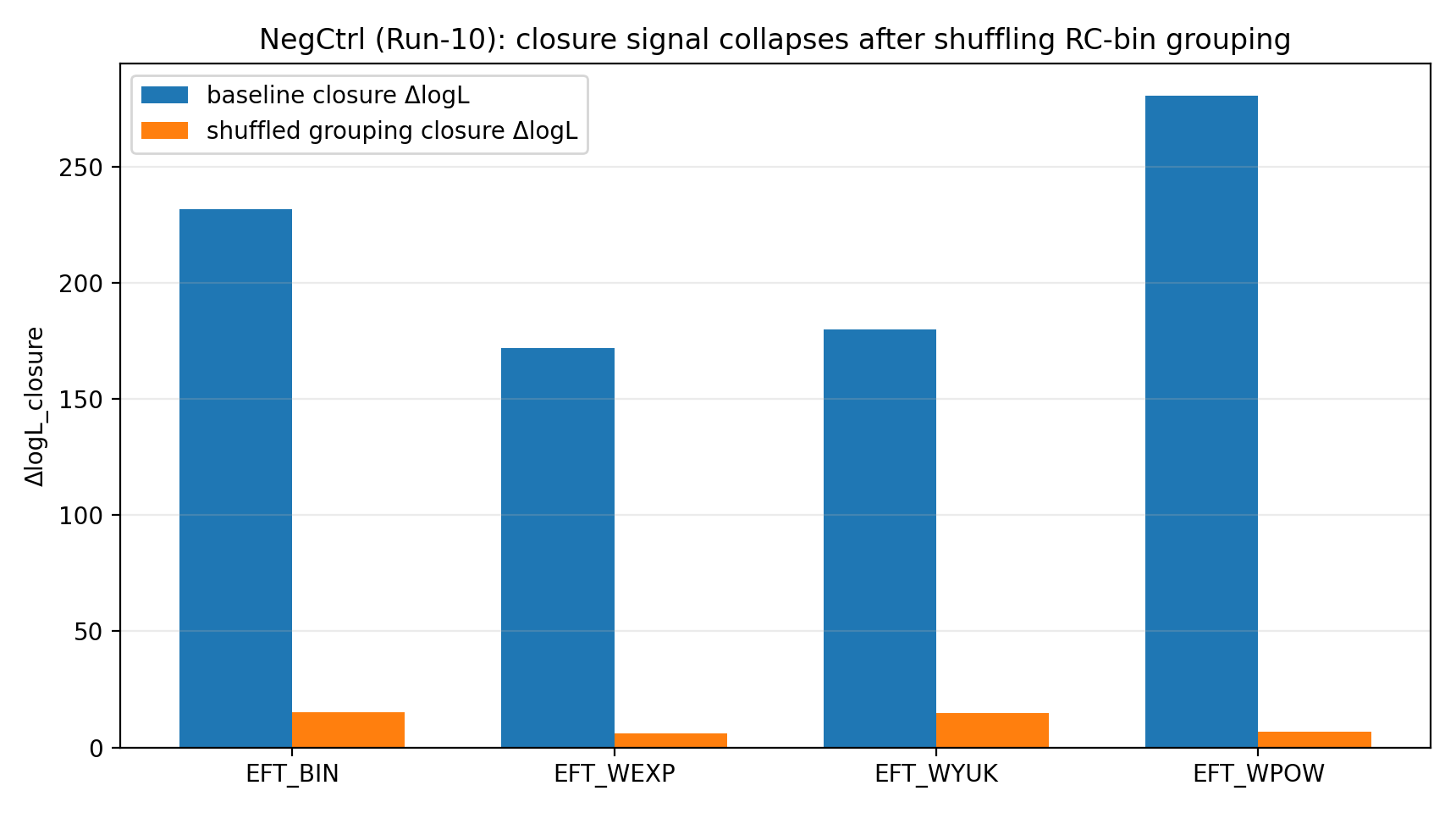
Figura R1 | Control negativo: la señal de cierre baja claramente tras el shuffle de los grupos.
Cómo interpretar esta figura |
Esta figura muestra que, una vez permutada la relación correcta de bins RC↔GGL, la señal de cierre baja de forma notable. |
Esto hace que el resultado de P1 se parezca más a una consistencia real dentro de la correspondencia entre datos que a una coincidencia numérica obtenible con cualquier correspondencia. |
8 | Robustez y controles: ¿cómo evita P1 que esto sea «solo un buen ajuste por parámetros»?
Un informe técnico suele ser cuestionado por estas dudas: ¿la ventaja proviene de una suposición de ruido, de una región central de los datos, de algún tratamiento de la covarianza o de sobreajuste? P1 responde con varias pruebas de presión.
Tabla 2 | Cómo leer la robustez y los controles negativos en P1
Prueba | Qué duda intenta descartar | Lectura |
Barrido σ_int | Si existe dispersión desconocida adicional en RC, ¿la conclusión sigue estable? | Al relajar los errores de RC, el orden y la escala de ventaja de EFT se mantienen estables. |
Barrido R_min | Si no confiamos plenamente en la zona central de las galaxias, ¿la conclusión sigue estable? | Tras recortar la región central, EFT mantiene una ventaja positiva. |
Barrido cov-shrink | Si la estimación de la covarianza GGL es incierta, ¿el orden es sensible? | Al contraer la covarianza hacia una matriz diagonal, la ventaja es poco sensible. |
Escalera de ablación | ¿EFT está ajustando a la fuerza mediante complejidad innecesaria? | EFT_BIN completo muestra necesidad según los criterios de información. |
Predicción LOO dejando fuera | ¿El modelo solo sabe explicar datos que ya vio? | Al dejar fuera un GGL bin, sigue mostrando una generalización relativamente fuerte. |
RC-bin shuffle | ¿El cierre proviene de una correspondencia real? | Al permutar los grupos, el cierre baja, apoyando la dependencia de la correspondencia. |
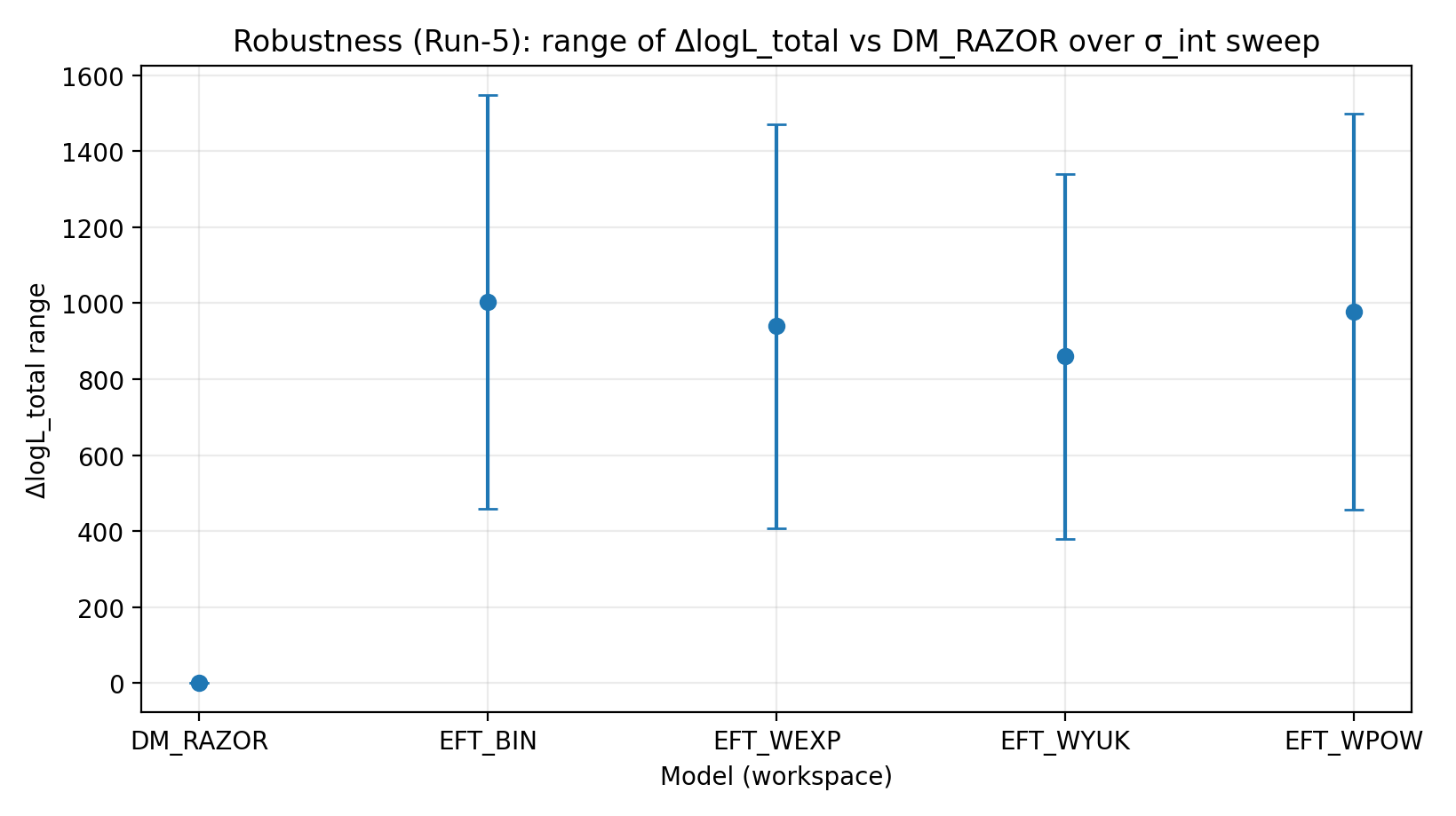
Figura R2 | Rango de ΔlogL_total bajo el barrido de σ_int (cuanto mayor, mejor).
Cómo interpretar esta figura |
Comprueba si la ventaja de EFT persiste al cambiar la hipótesis sobre la dispersión intrínseca de RC. |
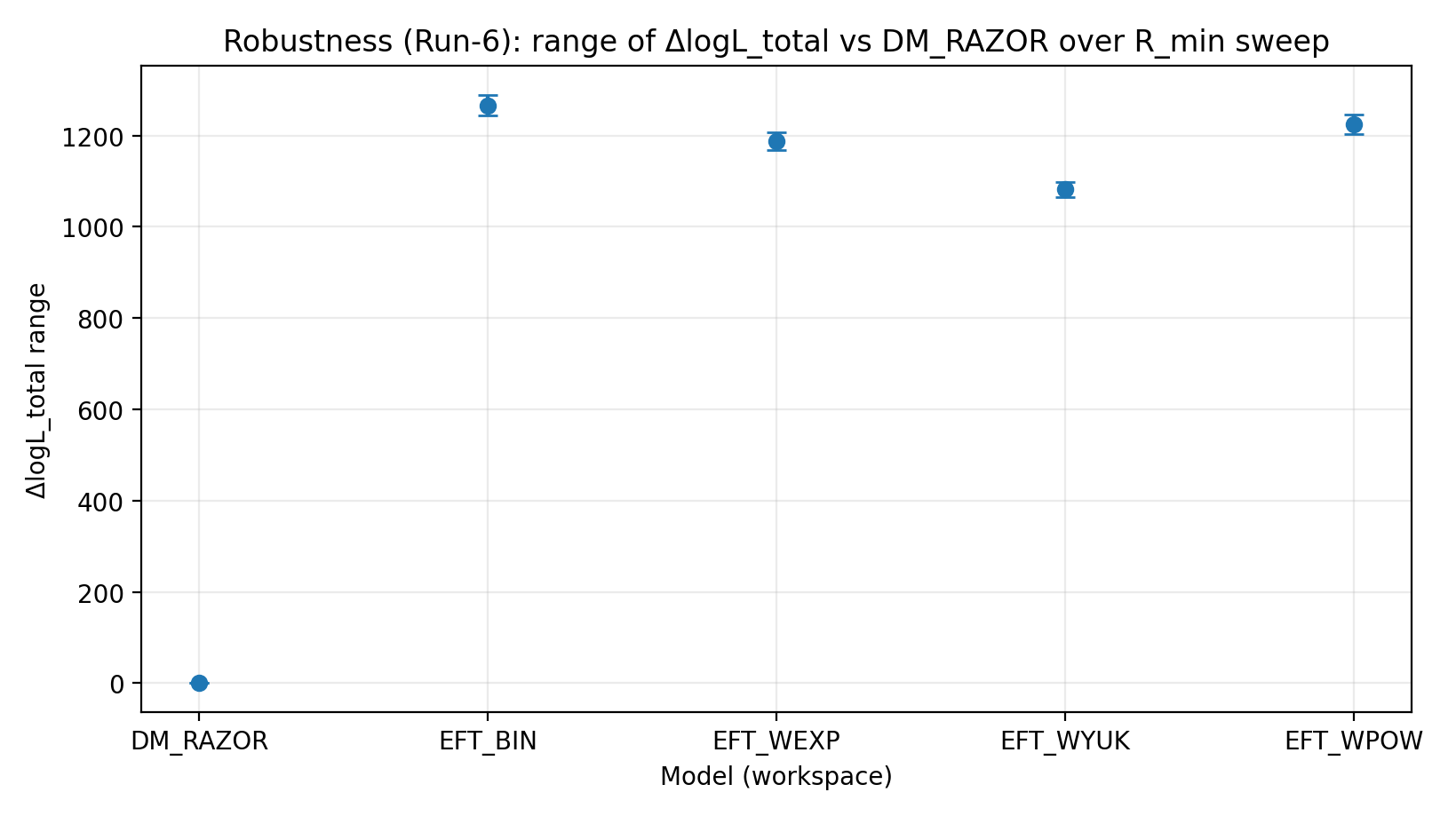
Figura R3 | Rango de ΔlogL_total bajo el barrido de R_min (cuanto mayor, mejor).
Cómo interpretar esta figura |
Comprueba si la ventaja de EFT sigue siendo estable tras recortar la región central compleja. |
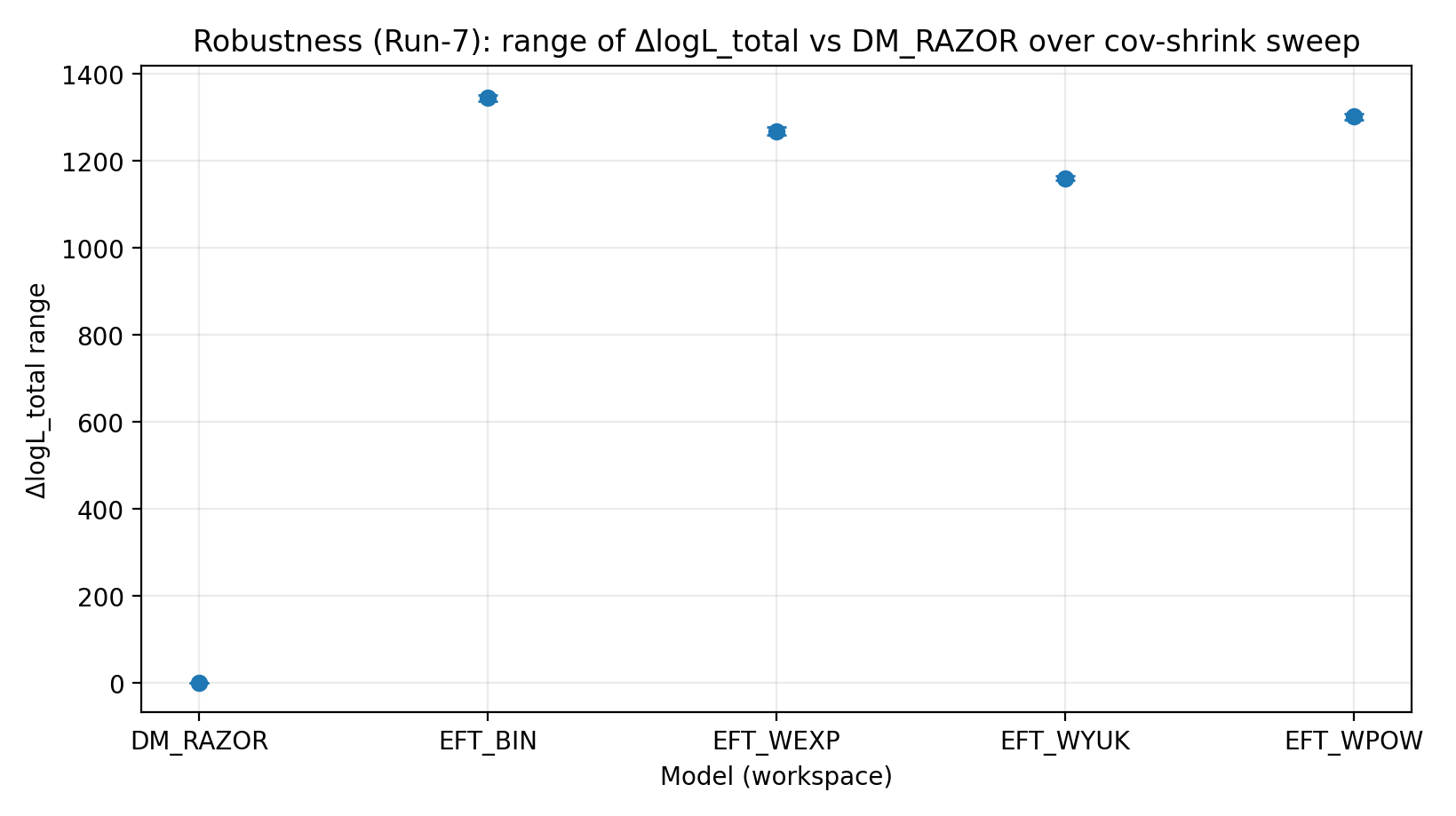
Figura R4 | Rango de ΔlogL_total bajo el barrido cov-shrink (cuanto mayor, mejor).
Cómo interpretar esta figura |
Comprueba si el orden es sensible a cambios en el tratamiento de la covarianza dla lente débil. |
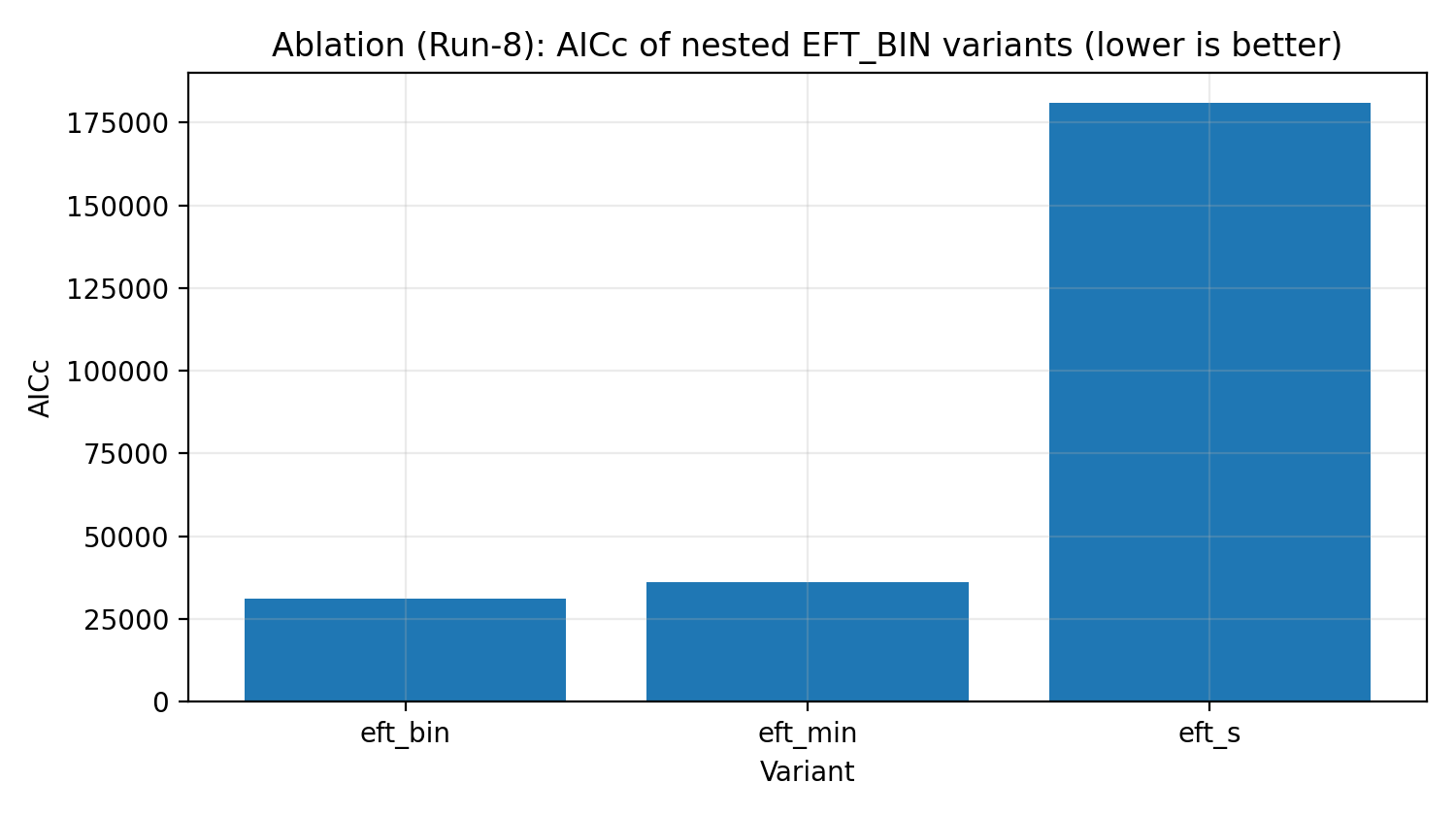
Figura R5 | Escalera de ablación de EFT_BIN (AICc, cuanto menor, mejor).
Cómo interpretar esta figura |
Comprueba si EFT_BIN completo es necesario para explicar los datos y no solo añade parámetros de más. |
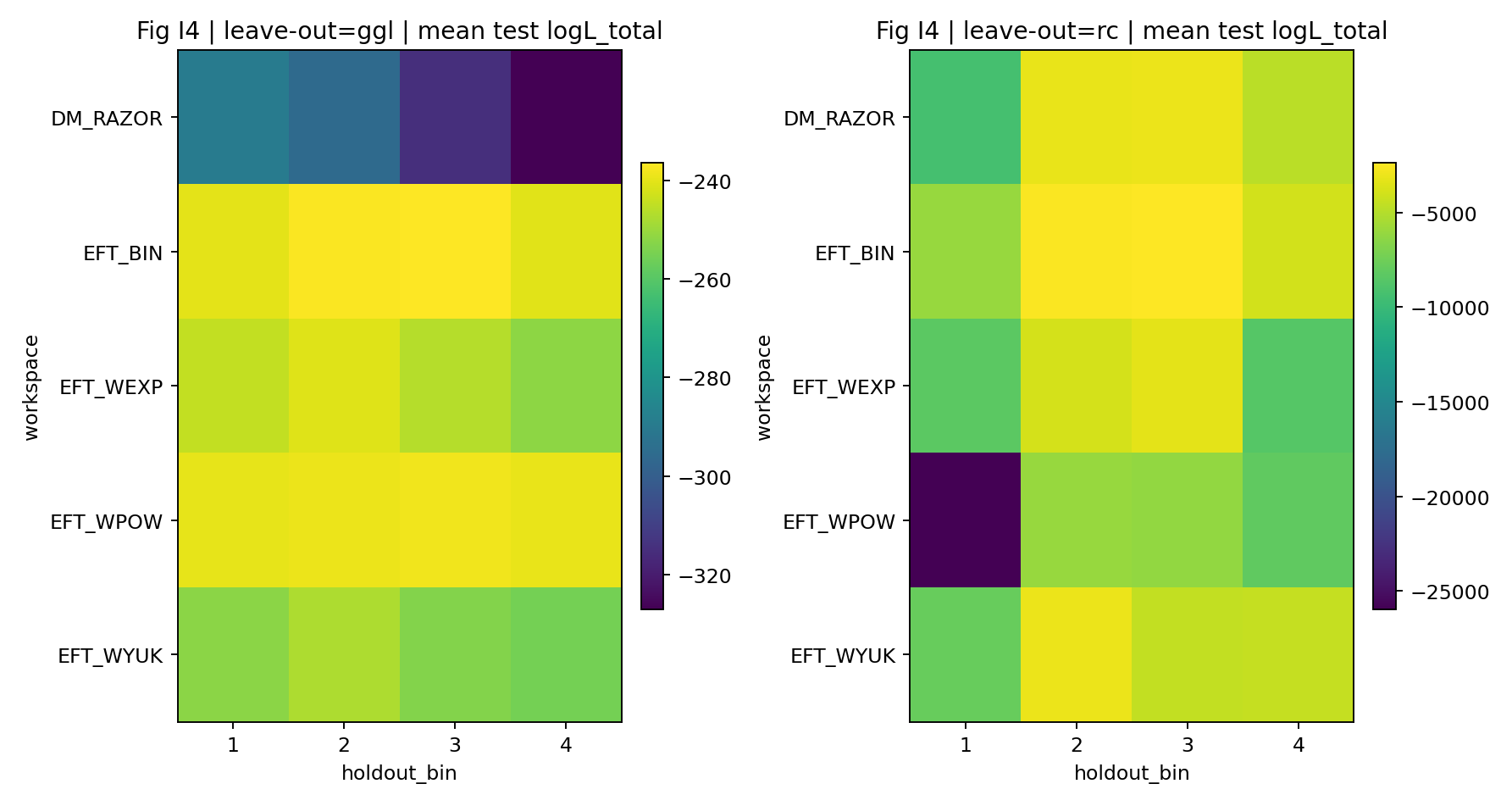
Figura R6 | LOO: distribución de log-verosimilitud al dejar fuera un bin.
Cómo interpretar esta figura |
Comprueba si el modelo conserva capacidad predictiva en GGL bins no vistos. |
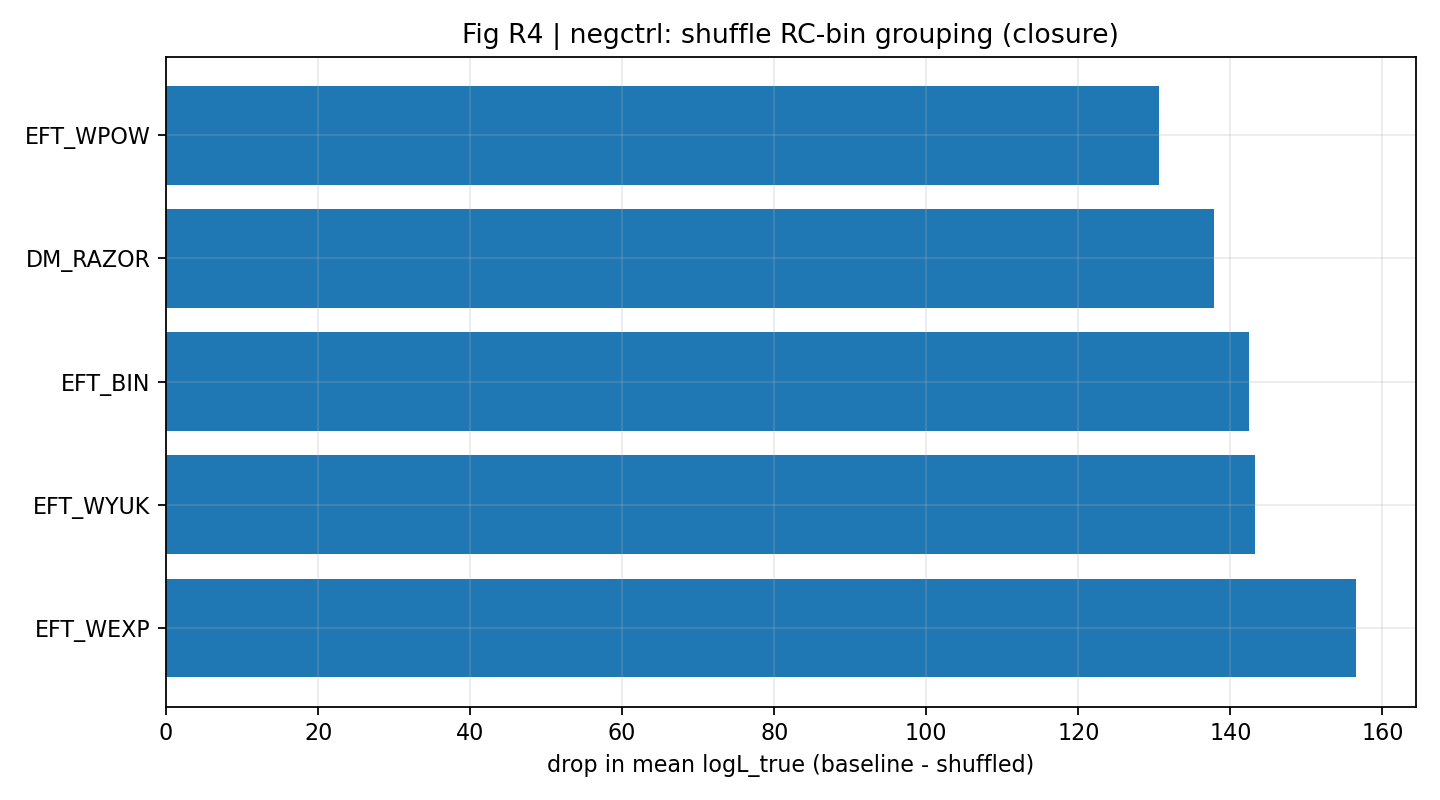
Figura R7 | Control negativo: el shuffle de la correspondencia reduce claramente la media logL_true de cierre.
Cómo interpretar esta figura |
Muestra además, desde la media logL_true, que el cierre depende de la correspondencia correcta entre conjuntos de datos. |
9 | P1A: por qué «hay varios modelos DM en el apéndice» es una corrección clave
Esta sección no pregunta «¿EFT solo ganó contra un DM_RAZOR mínimo?», sino: si reforzamos la línea base DM dentro de un rango de baja dimensión, reproducible y con libro de parámetros claro (P1A), ¿se reescriben las conclusiones de la prueba de cierre y del ajuste conjunto? En otras palabras, P1A busca reducir la objeción de que «solo se eligió una línea base DM demasiado débil» y llevar la discusión a esta pregunta: bajo un conjunto auditable de refuerzos DM, ¿sigue habiendo una diferencia en el desempeño de cierre?
El diseño de P1A no intenta agotar todas las posibilidades de modelado de halos LambdaCDM ni convertir el lado DM en una máquina de ajuste de alta dimensión e imposible de auditar. Elige refuerzos de baja dimensión, reproducibles y con libro de parámetros claro: scatter de concentración, contracción adiabática, feedback core, prior jerárquico de scatter c–M, proxy core de un parámetro, nuisance de calibración shear en lente débil y el DM_STD combinado.
Lectura principal de P1A |
Entre las tres ramas legacy, solo feedback/core aporta una pequeña mejora neta a la fuerza de cierre; SCAT y AC no generan una mejora neta de cierre. |
DM_HIER_CMSCAT, DM_RAZOR_M y DM_CORE1P tienen un efecto muy pequeño sobre la fuerza de cierre o no muestran una mejora neta significativa. |
DM_STD puede mejorar de forma clara el joint logL, pero la fuerza de cierre disminuye, lo que sugiere que mejora principalmente la flexibilidad del ajuste conjunto y no la potencia de predicción transferida RC→GGL. |
EFT_BIN sigue manteniendo en la Tabla B1 de P1A una fuerza de cierre más alta y una ventaja de ajuste conjunto; por tanto, la tesis central de P1 no debería simplificarse como «solo ganó al DM_RAZOR mínimo». |
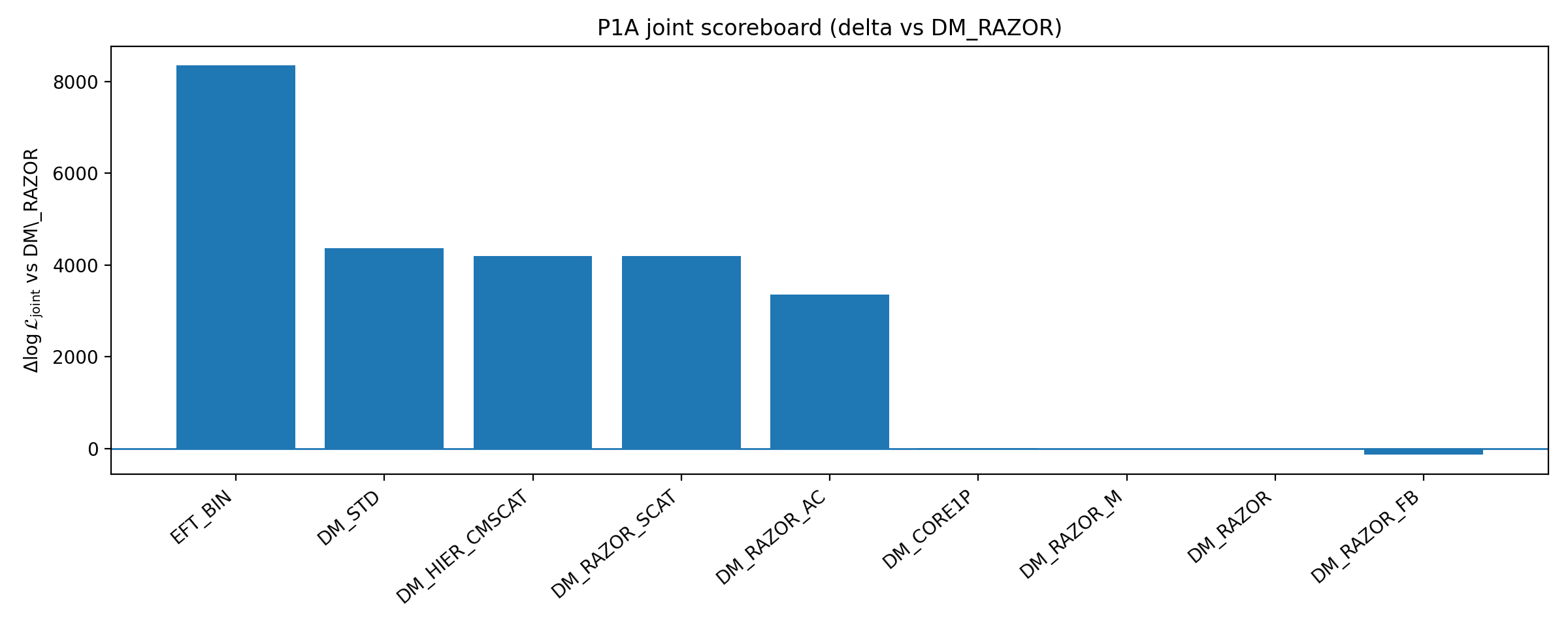
Figura B1 | Scoreboard P1A: ΔlogL de cierre y conjunto frente a la baseline (cuanto mayor, mejor).
Cómo interpretar esta figura |
Esta figura muestra el desempeño de varias ramas DM reforzadas frente a la línea base. |
Su significado no es «descartar todos los DM», sino mostrar que dentro del rango de refuerzos DM de baja dimensión y auditables elegido por P1A, el DM reforzado no elimina la ventaja de cierre de EFT_BIN. |
10 | Significado del experimento P1: por qué vale la pena hacerlo
10.1 Significado metodológico: situar el «cierre entre sondas» por encima del «ajuste de una sola sonda»
Las teorías a escala galáctica caen con facilidad en una discusión: si un modelo puede o no ajustar un conjunto de curvas de rotación. P1 eleva la pregunta un nivel: los parámetros que aprendiste de RC, ¿pueden predecir la lente débil sin volver a ajustar GGL? Así, P1 pasa de ser una «competición de ajuste» a una «prueba de predicción transferida».
10.2 Significado de transparencia: tratar la cadena reproducible como parte del resultado
Una contribución importante de P1 es publicar juntos los datos, las tablas y figuras, las etiquetas de ejecución, los controles negativos, el paquete de reproducción y la cadena de auditoría. Esto importa tanto a partidarios como a críticos: la discusión puede volver al mismo conjunto de datos públicos, la misma correspondencia, los mismos scripts y los mismos indicadores, en lugar de comparar solo eslóganes.
10.3 Significado físico: ofrece una prueba de presión fuerte para la dirección de «gravedad sin materia oscura»
En la dirección de la gravedad sin materia oscura, muchos modelos pueden explicar una parte de las curvas de rotación o de la RAR; lo más difícil es pasar también por la lectura de lente débil y mostrar, con controles negativos, que la señal depende de la correspondencia correcta. El sentido de P1 es colocar la respuesta gravitatoria media de EFT dentro de un protocolo parecido a un «examen externo»: RC es el campo de entrenamiento, GGL el campo de transferencia y shuffle el campo antitrampa.
10.4 ¿Es este un experimento importante para el campo de la «gravedad sin materia oscura»?
Con cautela: si el procesamiento de datos, el paquete de reproducción y el protocolo de cierre de P1 resisten la revisión externa, puede considerarse un experimento de cierre RC+GGL digno de atención dentro de la dirección de gravedad sin materia oscura / gravedad modificada. Su importancia no reside en la frase «derrotar la materia oscura», sino en ofrecer un criterio entre sondas que puede copiarse, desafiarse y ampliarse.
¿Existe ya un marco de predicción RC+GGL con un cierre igual de alto? |
Existen marcos y tradiciones observacionales relacionados: MOND/RAR organiza muy bien muchos fenómenos de curvas de rotación; el trabajo RAR con lente débil KiDS-1000 también comparó MOND, la gravedad emergente de Verlinde y modelos LambdaCDM; LambdaCDM también puede explicar parte de los fenómenos de lente débil/dinámica mediante conexión galaxia–halo, halos gaseosos y modelado de feedback. |
Pero la afirmación precisa de P1 no es «no existe ningún otro marco en el mundo capaz de explicar RC+GGL», sino que, bajo el propio protocolo público de P1 —correspondencia fija, cierre RC-only→GGL, control negativo shuffle, libro de parámetros y pruebas de presión P1A con múltiples DM—, EFT reporta un desempeño de cierre más fuerte. |
Dicho de otra manera, lo que más merece ser comprobado externamente en P1 es que propone un protocolo de comparación concreto y reproducible. Si en pasos posteriores MOND/RAR, LambdaCDM/HOD, simulaciones hidrodinámicas u otros marcos de gravedad modificada alcanzan bajo el mismo protocolo puntuaciones de cierre iguales o superiores, esa será una línea de trabajo muy valiosa. |
11 | Qué puede inferir P1 y qué no puede inferir
Tabla 3 | Límites de las conclusiones de P1
Se puede inferir | Bajo los datos RC+GGL de P1, la correspondencia fija y el protocolo de comparación principal, la serie EFT obtiene frente al DM_RAZOR mínimo mayor ajuste conjunto y mayor fuerza de cierre. |
Se puede inferir | Dentro del rango P1A de refuerzos DM de baja dimensión y auditables, varios refuerzos DM no eliminan la ventaja de cierre de EFT_BIN. |
Se puede inferir | El control negativo shuffle muestra que la señal de cierre depende de la correspondencia correcta entre conjuntos de datos y no aparece con cualquier correspondencia arbitraria. |
No se puede inferir | No se puede decir que P1 ya haya refutado todos los modelos de materia oscura. P1A no agota modelos no esféricos, dependencias ambientales, conexiones galaxia–halo complejas, feedback de alta dimensión ni simulaciones cosmológicas completas. |
No se puede inferir | No se puede decir que la teoría EFT completa haya sido probada desde primeros principios. P1 solo prueba la capa fenomenológica de respuesta gravitatoria media. |
No se puede inferir | No se puede decir que todos los errores sistemáticos estén descartados. P1 solo aporta evidencia de robustez dentro de las pruebas de presión y el alcance de auditoría listados. |
12 | Preguntas frecuentes: las dudas más comunes del lector general
P1: ¿Esto dice que «la materia oscura no existe»?
No. La conclusión de P1 debe limitarse a los datos, el protocolo y los modelos de comparación de este texto. P1A ya va más allá del DM_RAZOR mínimo, pero aun así no representa todos los modelos posibles de materia oscura.
P2: ¿Esto dice que «EFT ya está probada»?
Tampoco. P1 somete a prueba EFT como una parametrización de respuesta gravitatoria media y muestra un desempeño más fuerte en el cierre RC→GGL; el mecanismo microscópico y la teoría completa no son conclusiones de P1.
P3: ¿Por qué no hablar directamente en valores de significancia σ?
P1 usa una puntuación de verosimilitud unificada, criterios de información y diferencias de cierre. ΔlogL es una ventaja relativa bajo la misma regla de puntuación; no equivale a un único valor σ.
P4: ¿Por qué permutar RC-bin→GGL-bin?
Es un control negativo. Una señal real entre sondas debe depender de la correspondencia correcta; si después de permutar siguiera igual de fuerte, eso sugeriría sesgos de implementación o una señal estadística espuria.
P5: ¿Cuál debería ser el siguiente paso de P1?
Extender el mismo protocolo a más datos, más comparadores DM, errores sistemáticos más complejos y más marcos de gravedad modificada; en especial, permitir que equipos externos repliquen la prueba bajo el mismo indicador de cierre.
13 | Pequeño glosario de términos
Tabla 4 | Pequeño glosario de términos
Término | Explicación en una frase |
Curva de rotación (RC) | Relación radio–velocidad en el disco galáctico, usada para inferir la gravedad efectiva dentro del disco. |
Lente débil (GGL) | Medición de la distribución media de gravedad/masa alrededor de galaxias de primer plano mediante la distorsión estadística de formas de galaxias de fondo. |
Prueba de cierre | Usar las posteriores de RC para predecir GGL y compararlo con un control negativo de correspondencia permutada. |
Control negativo | Destruir deliberadamente una estructura clave para ver si la señal desaparece; se usa para descartar señales espurias. |
Halo NFW | Perfil de densidad de halo de materia oscura usado con frecuencia en modelos de materia oscura fría. |
Relación c–M | Relación entre la concentración c y la masa M de un halo de materia oscura; permitir o no scatter afecta la flexibilidad del modelo. |
DM_STD | Rama estandarizada de prueba de presión DM en P1A que combina varios refuerzos DM de baja dimensión y un nuisance de lente. |
ΔlogL | Diferencia de log-verosimilitud entre dos modelos bajo la misma regla de puntuación; un valor positivo indica que el primero es mejor. |
Covarianza | Descripción matricial de las correlaciones entre puntos de datos; en datos de lente débil normalmente debe usarse la covarianza completa. |
14 | Ruta de lectura recomendada y entradas de citación
1. Leer primero las secciones 0–2 de este texto para construir la pregunta de P1 y la posición prudente de EFT dentro de P1.
2. Después mirar las Figuras S3 y S4, y las Tablas S1a/S1b, para entender la fuerza de cierre, el ajuste conjunto y el control negativo.
3. Si la preocupación es si la línea base DM es demasiado débil, ir directamente a la sección 9 y a la Tabla B1 / Figura B1.
4. Para una revisión técnica, volver al informe técnico P1 v1.1, al suplemento Tables & Figures y al full_fit_runpack.
Entradas principales de archivo |
Informe técnico P1 (nivel de publicación, Concept DOI): 10.5281/zenodo.18526334 |
Paquete completo de reproducción P1 (Concept DOI): 10.5281/zenodo.18526286 |
Base de conocimiento estructurada de EFT (opcional, Concept DOI): 10.5281/zenodo.18853200 |
Nota de licencia: el informe técnico usa CC BY-NC-ND 4.0; el paquete completo de reproducción usa CC BY 4.0 (según el informe técnico y el archivo de Zenodo). |
15 | Referencias y contexto externo
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.